What is the NonStop?
Watch: HPE NonStop Solutions: Always on and always adapting
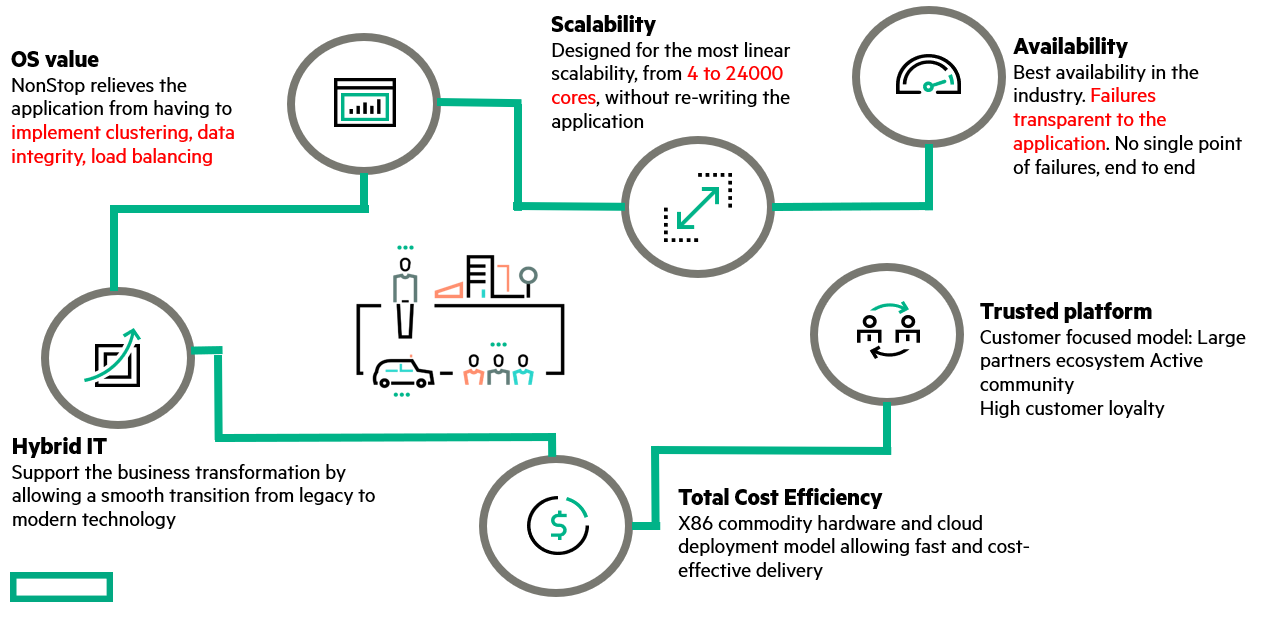
NonStop is a platform that runs some of the world’s most exciting workloads in our day-to-day life. From producing luxury cars, to making payments in our grocery shops, NonStop is the platform that lets our customers, and their engineers get their sleep, while their mission-critical applications continue in data centres and on private clouds.
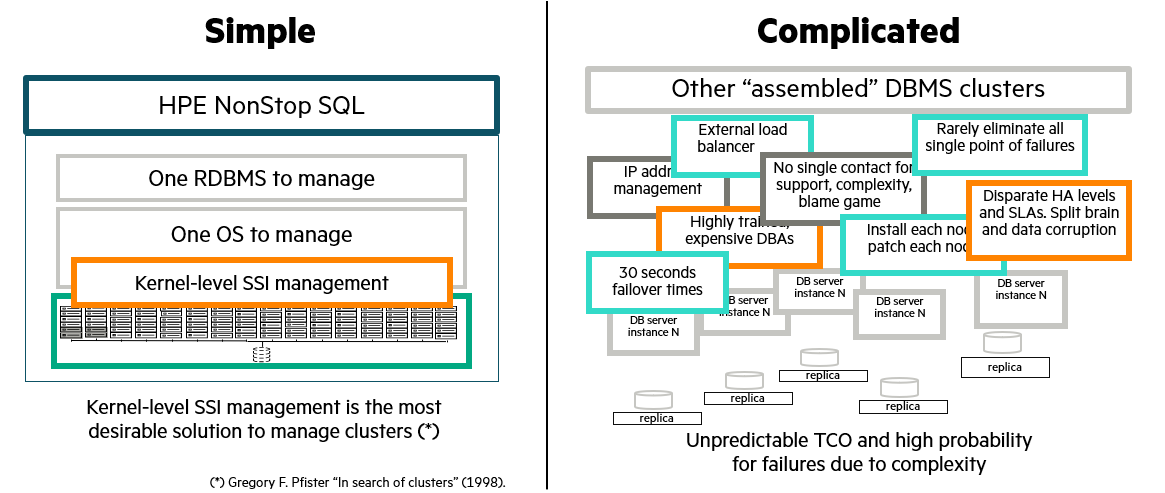
Many Nodes, One System Administration
Typically, a system of multiple nodes would require a team of administrators to maintain the cluster and ensure load is balanced when there is failure. The more nodes we have, the more complex the system.
Not for the NonStop.
On this platform, a cluster of multiple nodes (we're talking about up to 1000+ CPUS) is seen as one single system image. We do not worry about version control across the nodes, and any code to handle failures - data and processes are mirrored across the entire system and a NonStop system of many nodes is seen as one.
Patented Process Pair Technology
The NonStop OS runs applications and its processes using the MPP (massively parallel) architecture, which is a shared-nothing architecture, with mirrored paths between instructions etc.
It is IDC Availability Level 4 and provides continuous, uninterrupted operation in the event of failure.
This means we specialise in applications that require clustering for highest availabilities.
The NonStop OS has patented its fault-tolerant and self-healing technology by allowing paired processes to takeover when a primary component fails.
What happens when there is failure?
-
Component fails.
-
Mirrored component takes over the role of failed component.
-
The failed component reboots itself, and sets itself as the mirror.
-
Processes are mirrored once again.
The process can repeat as many times as possible as necessary, and ensures the highest level of availability qualified by IDC.